
Building a private cloud on Linux Containers
Motivation
At our company, we develop our own software products that we offer to our clients and often also run ourselves. So far our company has operated its IT infrastructure — about 30 virtual servers—on a public cloud, specifically on MS Azure. We have also run our infrastructure on Amazon AWS and Google Cloud Platform in the past. Our experience of operation has been mostly positive, however, as the company is growing, the operation of the public cloud has become unnecessarily expensive. Our products are processing a large amount of data, in the range of terabytes a month, and such a volume can significantly raise the price of the public cloud. We do not want to constrain our creativity with "too expensive" servers/drives/CPUs.
Cost comparison of public cloud vs. private cloud
In the beginning, we calculated the costs of our infrastructure on the public cloud and then how much private cloud cost would be. We, of course, included costs for connectivity, electricity, premise rental, etc.
| Item | Public Cloud | Private Cloud |
|---|---|---|
| Build cost (one-off) | $ 0 | $ 8082 |
| Monthly cost | $ 3054 | $ 645 |
| Total cost in 1 year | $ 36648 | $ 15822 |
| Total cost in 3 years | $ 109944 | $ 31302 |
| Total cost in 5 years | $ 183240 | $ 46782 |
The cost aspect, of course, was not the only reason why we started building our own private cloud. An important argument was the fact that building the container's private cloud was a unique experience that we wanted to gain. It sprouted from curiosity. This hands-on experience allows us to be more relevant to our clients and it enables us to make more educated decisions about the design of our software.
Of course, we realize that things are not always perfect. We know the common pitfalls: the private cloud means a lot of worrying about HW, it will one day be obsolete (phasing out), HW components will fail, and maybe there are unknown hidden costs. However, these facts have not deterred us from constructing one.
Linux containers
Sometimes we build on-premise IT environments (virtual servers, containers or physical hardware) for our clients, and we learned here that using Linux container technology can achieve far higher infrastructure density than conventional virtualization. This means that we can deploy more software on one physical server without a negative impact on the performance of the final IT environment. Check out this performance comparison of containers vs virtual machines. The article states a factor 14.5x in terms of the greater the density. We can subjectively confirm this value. It translates to 14.5 times less infrastructure and hence 14.5 times less operating costs.
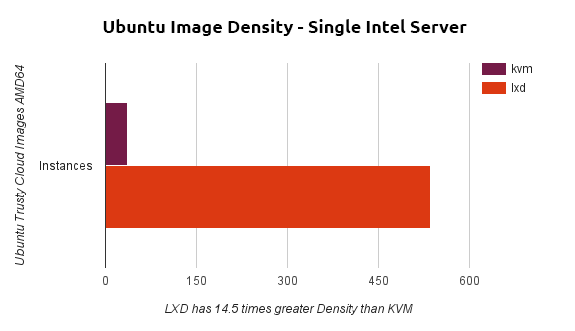
Picture: LXD (Linux containers) vs. KVM (virtual machines) density comparison.
Another important aspect is the high flexibility, which means that, if a change in the distribution of the infrastructure is needed (e.g., because the load on the system has changed), containers can be very quickly moved around to rebalance the load. Classical virtualization technologies handles that situation order of magnitude worse.
So we decided to build a private cloud using Linux containers. Linux containers have been around for almost 15 years and are now starting to gain incredible momentum with the rise of application containers such as LXC, Docker, and Rocket. Linux containers offer incredible flexibility, security, and (most importantly) speed to market.
After the initial evaluation and testing, we decided on LXC for the new LXC/LXD. LXD is a daemon that provides a REST API to manage LXC containers. A second option was Docker. LXC is opposed to the Docker and is designed for virtualization of operating systems (vs. Docker targeting on deployment application). Practically there’s not a big difference, both technologies are based on the same foundation and it is very easy to use Docker in LXC and vice versa. For instance, it is possible to install the LXC container according to commands from the Dockerfile (manually, of course). The Docker has a bigger ecosystem and more tools, and of course, a huge library of ready-to-use containers of different applications, databases, etc. Finally, it is important to note that choosing LXC over Docker is not an irreversible decision. Docker or rkt may also be added to a private cloud later.
Architecture
The main requirement for private cloud architecture was high availability. So we decided to set up two locations. We planned three compute nodes in each location as a starter. This means that each location is resistant to the failure of one node and the whole is resistant to the failure of a single location.
The high availability requirement is addressed on the application layer. This means that, for example, the MongoDB database server is installed in four containers that are located on different nodes and in different locations. MongoDB databases are organised with the so-called replica set. This provides automated failover by master-slave replication.
Web applications are then deployed to multiple containers and a related application traffic is balanced via front proxy servers, either in active-active mode or in active-passive, depending on the specific web application.
Another important requirement was a need to design everything so the private cloud could grow. In the future, we will add another site and, of course, upload compute nodes.

Picture: The architecture of the private cloud.
Compute
Compute nodes represent the foundation of the whole private cloud. These are the physical machines on which the Linux operating system is installed in the distribution of Ubuntu 16.04 LTS (Xenial Xerus). It is possible to use standard server hardware, however, we conducted an economic cost/value analysis and we found out that, by far, the best value is achieved by deploying the AMD Ryzen CPU. Alternatively, the AMD Threadripper also ran well, but we decided to go for a number of relatively smaller nodes over a lower number of bigger machines. Intel had only half the score, so the decision was unambiguous.

Table: Cost/value analysis for various CPU architectures.
Our experience has shown that the usual bottlenecks are the size of RAM and the speed of disk operations (IO). Number of CPU cores or their speed does not pose a problem and compute nodes have enough performance. Each CPU of Ryzen has 8 physical kernels or 16 hyper-threading cores. From the traffic we see, this whole node gives more than enough power.
| Item | Node 1 | Node 2 |
|---|---|---|
| CPU | AMD Ryzen 7 1700X | AMD Ryzen 7 1800X |
| Motherboard | ASUS PRIME X370-PRO | MSI X370 SLI PLUS |
| RAM | 4x Ballistix 16GB 2400Mhz | 2x Crucial 32GB KIT DDR4 2400MHz CL17 |
| System drive | Samsung 960 EVO 250 GB | SSD Disk WD Green 3D NAND SSD 120GB M.2 |
| Data drive | Seagate SkyHawk 4TB | Seagate SkyHawk 3TB |
| Data drive | WD Purple 4TB | Seagate SkyHawk 3TB |
| Power supply | Corsair VS450 | Fortron SP500-A |
| Graphics card | SAPPHIRE R5 230 1G D3 | SAPPHIRE R5 230 1G D3 |
| TPM | ASUS TPM-M | ASUS TPM-M |
| CPU fan | ARCTIC Alpine 64 Plus | ARCTIC Alpine 64 GT |
| Chasis | SilentiumPC Brutus M10 | SilentiumPC Brutus M10 |
Table: Examples of various node configurations we used in the build.
It's clear from the table that we've decided essentially on gaming hardware. It represents an optimal sweetspot of performance, quality, and price. One compute node delivers 16 hyperthreading CPU cores and 64GB of RAM.

Disk storage is currently local over SATA. We use ZFS, which is a highly flexible and natively supported by LXC containers. This allows us to create a snapshot, clone containers online, and so on.

Picture: The detail look at compute nodes.
On each compute node we deploy LXC containers with the hosted application. It could be for example HTTP Apache server, NGINX, TomCat or the application server written in Python that uses, for instance, our framework ASAB. Other containers run database servers or message queue servers. These are better to form into a cluster, which spread over all compute nodes. Such a converged approach provides high-availability, excellent scalability and so on. It means that if any application in the private cloud needs, e.g., MongoDB, it doesn't require to deploy MongoDB into an application container nor to deploy dedicated MongoDB container. The application connects to an existing MongoDB cluster, to a freshly created new database instance. Currently, we operate MongoDB cluster service, Rabbit MQ cluster service, and ElasticSearch cluster service. We plan to introduce PostgreSQL and maybe MySQL (or MariaDB).
Compute nodes are ready for GPU cards installation, and at least 3 GPUs can be added to each node and used, for example, in machine learning or AI applications. We have tested this path on entry-level graphics cards, which are (of course) very weak from the point-of-view of performance, but they are already being used by OpenCL.
We struggled a bit due to a Ryzen bug. We used the Linux kernel that caused so-called soft lockups—details can be found e.g. here, here or here. We finally solved this problem with the help of zenstates, specifically by turning off the so-called C6 Power Mode of Ryzen CPU. This apparently results in a slightly increased consumption of electricity.
 Picture: The screenshot of a compute node console with Ryzen soft lockup bug
Picture: The screenshot of a compute node console with Ryzen soft lockup bug
Network
The private cloud runs on a private IPv4 range of 10.17.160.0 / 17 where, for each location, we reserved the /20 IPv4 block or 4094 IPv4 addresses.
Locations are very close to the Internet backbone network (<4ms) but they do not have public IP addresses.
Each container typically receives its own IPv4 address from this private range using a DHCP server.
A container can be migrated between compute nodes in one location without changing its IP address.
If a container is migrated between locations, the IP will change.
IP addresses are a container assigned by a DHCP server and the assigned IP is linked with the container name.
This allocation is then transferred to the private cloud server's DNS server, so it is accessible for DNS resolution to the rest of the cloud.
This means that you can address the container by its name.
This elegantly solves the problem with a change of the IP address when a container is migrated from one location to another.
We have learned this functionality from the dnsmasq server, but we had to extend that to a shared DNS server.
In the future, we also want to add IPv6 support, which should not be a huge problem. Another future improvement of the networking will be an introduction of VLANs so that network traffic is segmented on the L2 level on our cloud.
Networking management at each location is provided by the network node. This node is also responsible for routing and firewall functions.
Hardware is PC Engine APU2. We use a version with 4GB RAM and 3x Gigabit Ethernet NIC. It has an excellent network throughput. We use Linux Ubuntu 16.04 LTS (Xenial Xerus).
| Item | Specifications |
|---|---|
| CPU | AMD GX-412T (4 cores) |
| RAM | 4 GB DRAM |
| Ethernet | 3x i210AT LAN (1 GigE) |
| SSD | M-Sata 16GB MLC, Phison S9 controller |
| HDD | SATA 500GB |
We run NTP, DHCP, and DNS server, IP tables based firewall, VPN client, and telemetry and log collection on the network node. The cherry on the cake is that LXC/LXD is also installed on the network node and so it is possible to deploy containers here too. The internal network of each location is operated on a Gigabit Ethernet. We plan to upgrade it to 10 Gigabit Ethernet eventually.
Front
The private cloud interface with the Internet is implemented via so-called front nodes. These are small virtual machines that we have leased from various providers. Each one of them is assigned one or more public IP addresses and uses NGINX and HAProxy again in the LXC containers. NGINX serves as an HTTPS reverse proxy and load balancer, which forwards HTTP(S) requests to application servers on compute nodes. HAProxy serves a similar purpose at the TCP or TLS level for AMQP protocol (MQ). High availability of front nodes is solved by DNS balancing.
VPN is used to connect private cloud locations with front nodes. We use OpenSSL and Wireguard. The later seems to be a better for fixed point-to-point setups.
Conclusion
At the time of writing this article, we have the first location built and running.
Current consumption on one compute node is about 80 Watts. This means that the monthly cost of electricity consumption on a single node is about $70. We assume that, when it gets bigger, consumption can be reduced to 200 Watts, which is a monthly charge for electricity at $175.
One of the next step is to start building a storage nodes. We plan to use CEPH, this technology is directly supported by LXC/LXD. I appreciate this experience. The result has highly exceeded my original expectations. We have learned a lot. Operation of the private cloud is very fun and flexible and we have gained a whole lot of new ideas about what to do with the future. We are producing much more 'container-friendly' software products thanks to this exercise. This means we can build more flexible and scalable software.

Most Recent Articles
You Might Be Interested in Reading These Articles

Key Areas and Best Practices to Focus for Mobile API Security
With APIs (Application Programming Interfaces) becoming a crucial factor in any web or mobile application, security feels more like a journey than a destination. Of all the constituents that encompass an application, API gateway offers easy access points for a hacker to break in and steal your data. A single error in API can cause immense problems for any organization using your API.
Published on November 22, 2016

SeaCat Mobile Secure Gateways' Performance Test
We decided to perform this test to validate our architectural, design and implementation decisions in regards to SeaCat performance. Our goal was to build the best-in-class product using the most advanced techniques to deliver highest possible throughput yet not compromising the security of the communication. Results of the test have been fed back into our development team to improve further overall performance characteristics of the solution.
Published on July 21, 2014

What’s The Difference Between Seacat and VPN?
One of the most common questions people asked us is if SeaCat some kind of a VPN? It's not. Virtual Private Network (VPN) extends a private network across a public network, providing secure connectivity from/to a mobile device. Every application on this device, thus now has access to the private network through the channel opened by VPN. This is safe up to a certain level because it is almost impossible to ensure the integrity of every application on the devices. Especially now when there are apps for everything, and users can download them from Google Play and the Apple store.
Published on November 25, 2014